
Introduction
Message-driven architectures are ubiquitous in enterprise integrations. Messaging capabilities are typically provided by a separate software system called message-oriented middleware (MOM). The current trend for MOMs is to use Message Brokers that can receive messages from multiple sources, determine the correct destination, and route the message correctly. In more complex situations, numerous message brokers are combined in a hierarchy1.
Modern message brokers allow reliable, flexible, high available, asynchronous, and fast inter-communication among distributed services or application components.
A typical scenario in a distributed application is to have a requester service that sends a command message to another processor service to perform some action. However, it often happens that the execution of the requested action fails, and the processing should be retried several times, possibly using exponential backoff, before renouncing and reporting an error2.
This re-attempt to execute logic goes under the name of Retry logic, and it is often supported by modern message brokers, although with different levels of sophistication.
RabbitMQ is one of the most advanced and widely deployed open-source message brokers.
There are many situations where RabbitMQ is the chosen message broker for Mule integrations, e.g., when:
-
RabbitMQ is already in use in other integrations
-
We want to have complete control of the message broker deployment and operations
-
One of the RabbitMQ 's advanced features, e.g., routing, makes our new integrations easier
-
Anypoint MQ, Mulesoft's integrated cloud messaging service, is unavailable in the region where we deploy our applications, e.g., in the China region.
Unfortunately, RabbitMQ does not include a Retry logic out-of-the-box, and further work is needed to implement this functionality. In this post, we show how to design and implement a Retry Logic with RabbitMQ and the Mule AMQP connector.
We start with a gentle introduction to RabbitMQ and how to use it in a Mule application through the AMQP connector. We follow by describing how to retry a failed processing in distributed and message-driven systems. Then, we illustrate our solution to implement a Retry logic with RabbitMQ. Finally, we demonstrate the solution with code and step-by-step instructions.
RabbitMQ Primer
“RabbitMQ is a messaging broker - an intermediary for messaging. It gives your applications a common platform to send and receive messages, and your messages a safe place to live until received.”
In RabbitMQ, messages are routed through Exchanges that are bound to Queues.
A publisher only needs to specify the exchange name and routing key to publish a message successfully.
When a message arrives in a queue and a message consumer is available, it consumes the message. This is illustrated in Fig. 1.
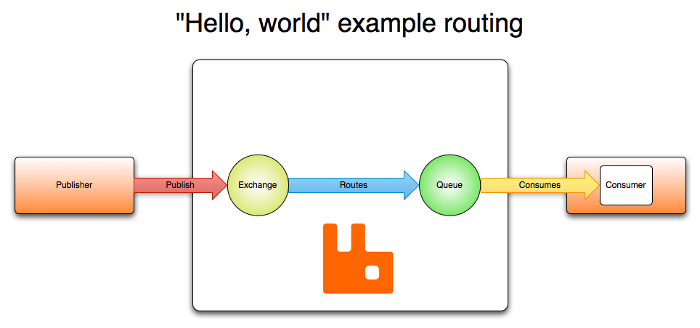
Fig. 1. RabbitMQ’s routing example. Image by: https://www.rabbitmq.com/tutorials/amqp-concepts.html
There are four Exchange types for different types of routing:
-
Direct (where an exact match with the routing key on the message is needed)
-
Fanout (don’t use routing key, send to all bindings)
-
Topic (pattern matching with routing key on the message)
-
Header (usually avoided since its low performance)
Finally, RabbitMQ supports several protocols. AMQP is the primary protocol supported by the broker. Mulesoft provides a fully compliant AMQP v 0.9.1 connector that we can use to connect to RabbitMQ.
Retry a failed processing in message-driven systems
In distributed and message-driven systems, we should embrace the fact that the processing of a requested action, or of an action triggered by the reception of an event, may fail for different reasons, and the processing should be retried several times3.
Let's consider a common scenario where a requester service sends command messages to another processor service to perform some action.
This simple scenario can be implemented using a Request-Reply pattern. Fig. 2 helps to illustrate this.
A Requester component sends command requests (e.g., new_order) through a Request channel and listens for responses in a different Reply channel. A Processor component consumes from the Request channel, processes the requests, and publishes to the Reply channel on a successful computation. In case of errors, instead, it publishes to an invalid request or a process error channel. The difference is that we use the invalid request channel to diagnose integration issues (e.g., the Requester missed to send a required field in the message) and a process error channel to report on application errors due to the processor. Finally, every channel has a Dead Letter Queue, used when the messaging system can't deliver a message.
To handle processing failures, we use two Retry channels:
-
A retry channel for the requester that has the responsibility of the requested action and should retry in case of an expired timeout.
-
A retry channel for the processor, added for technical reasons. In fact, the processor has greater knowledge of a failure's causes and can better tune retry's parameters or decide to do not to retry at all.
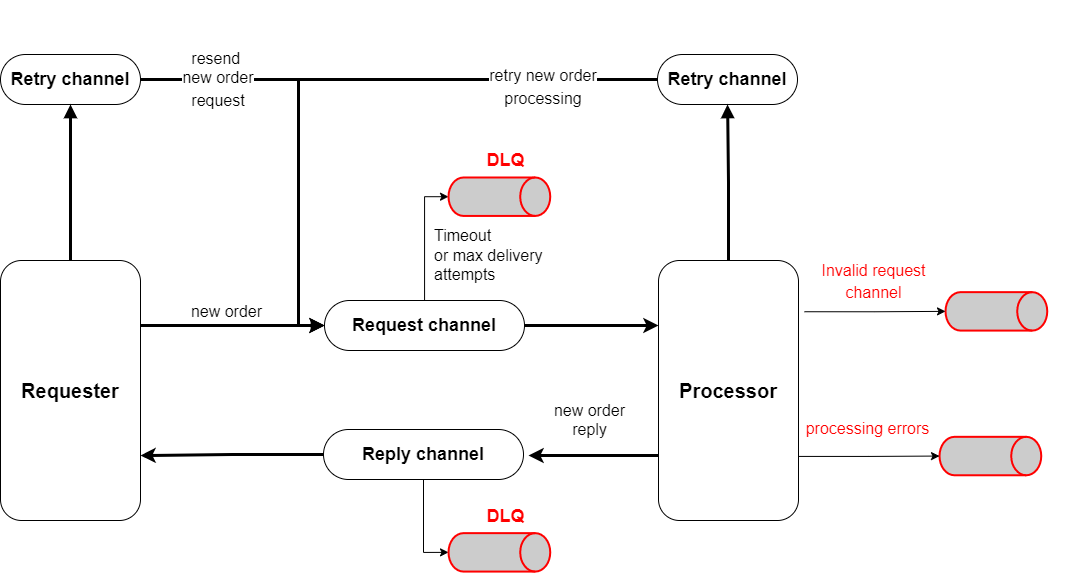
Fig. 2. A command implemented with the Request-reply pattern and retry queues.
Designing a Retry Logic for RabbitMQ
The problem
A message in RabbitMQ is immutable: once a message is produced, none of the message, including the header, properties, and body, can be altered by an application unless republished as a new message.
This means that we can’t add a retry counter in the message.
A possible solution
Our solution is based on two components:
-
Using the RabbitMQ Delayed Message Plugin that introduces delayed exchanges: a kind of exchange that supports a parametric message delivery delay.
-
Adding a retry queue with a small (possibly zero) queue’s time-to-live (TTL). A message arriving in the retry queue will be immediately rerouted to its dead letter queue (DLQ).
Then, imagine that a command message arrives in the request queue and is consumed by the Processor. If the requested processing fails but should be retried, we:
-
publish a new message to the retry queue through a delayed exchange. The new message contains two additional headers, "x-delay" and "x-retry-count" . "x-delay" tells the delayed exchange how much to wait before delivering the message. This is incremented following an exponential backoff mechanism. "x-retry-count" is the retry counter. Then, we acknowledge the old message so it will be removed from the broker.
-
After the "x-delay" time expires, the new message will be delivered to the retry queue and immediately rerouted to the original request queue.
-
Finally, if a maximum number of retries is reached, we will stop the retry logic by, e.g., rejecting the received message (or by publishing an error message in an error queue and acknowledging the original message).
Example implementation
For example, Fig. 3 illustrates a RabbitMQ’s design diagram of the command example shown in Fig. 2. In this design, we only implemented the retry strategy of the processor (the implementation for the requester is similar). Further, we ignore the invalid channel queue. Finally, to improve information hiding, we used an internal Exchange for supporting private operations. In fact, internal Exchanges can’t be accessed from outside but only from other Exchanges.
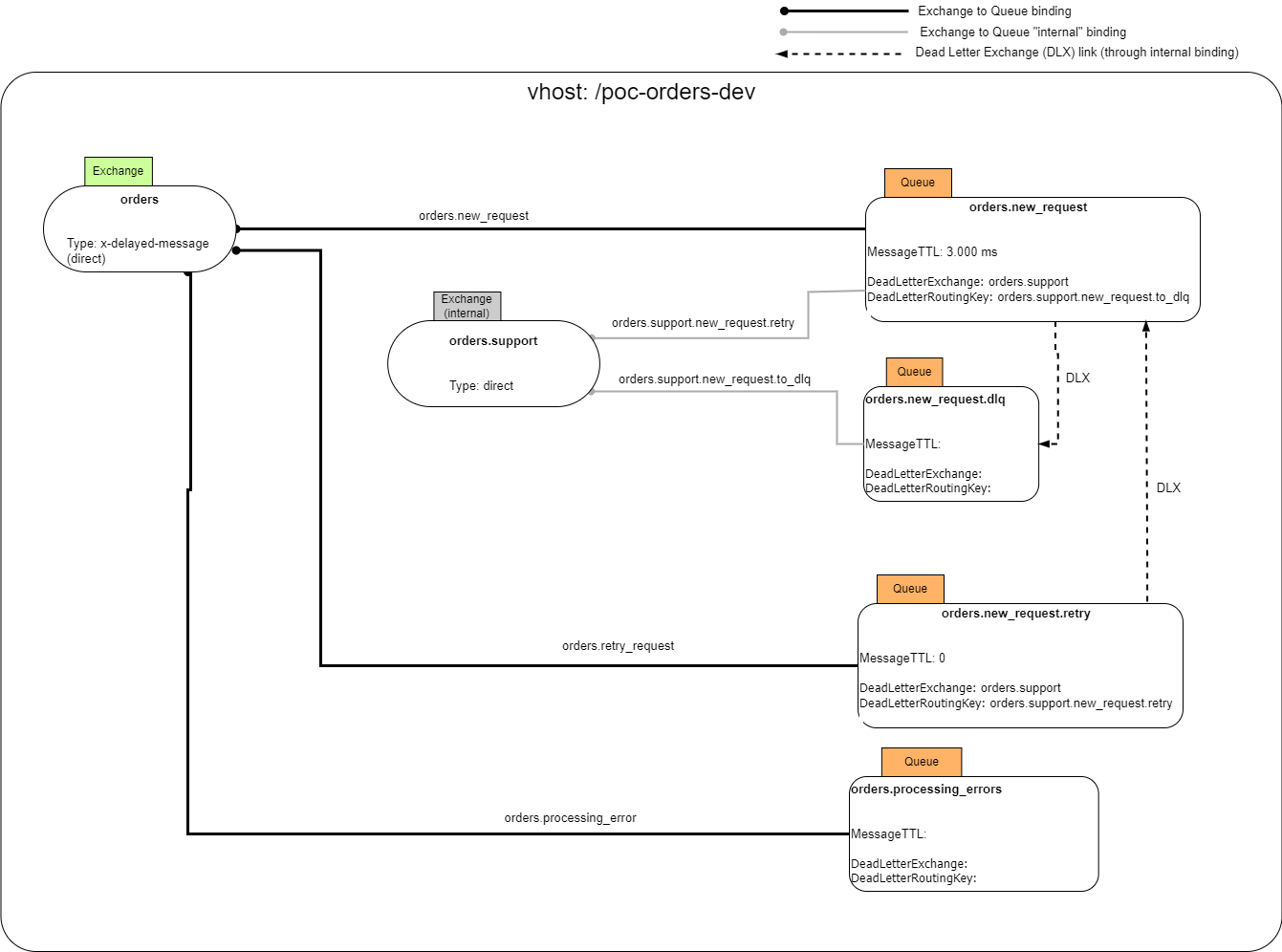
Fig.3. Example implementation in RabbitMQ of the command example shown in Fig.2
Demo Code
Demo code with step-by-step instructions is included in the Mulesoft Meetups Cosenza repository.
The demo code is a single Mule 4 application consisting of two main flows that implement the use case of Fig. 4:
-
A Requester flow that publishes new order messages to RabbitMQ through the orders.new_request routing key
-
A Processor flow that:
-
consume new order requests from the order.new_request queue
-
processes the received requests and possibly retry failed processing using exponential backoff. Retry messages are published using the orders.retry_request routing key-
-
publishes error messages with the orders.processing_errors key (we use this route to address requests that should not be retried because of, e.g., a permanent error)
-
reject requests that should not be retried because of an exceeded max number of retry limit (these messages are sent to a Dead-Letter-Queue)
-
Usually, Requester and Processor are different applications. For ease of illustration, we do not implement a response channel or an invalid channel in our demo.
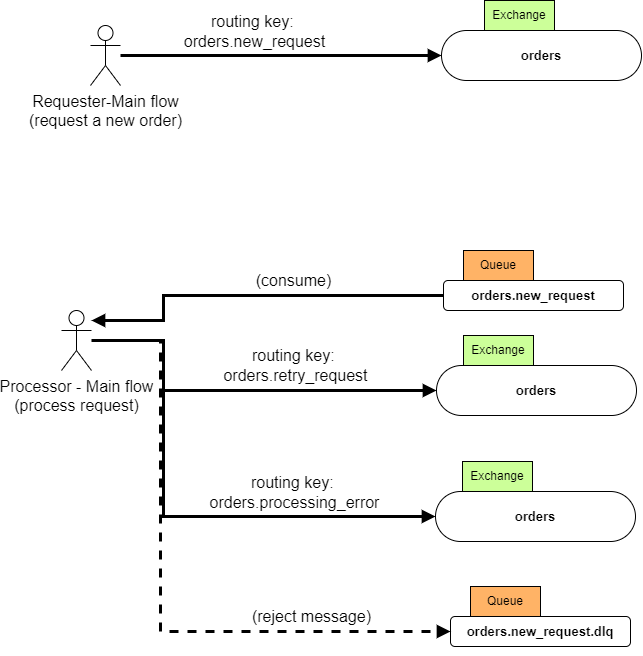
Fig. 4. Use case for the Mule demo application.
Written by Andrea Capolei, Principal Solutions Architect and Mulesoft Meetup leader.
Notes
1 For a thorough discussion on enterprise integration patterns with messaging systems, see the book “Enterprise Integration Patterns: Designing, Building, and Deploying Messaging Solutions” by Gregor Hohpe and Bobby Woolf.
2 In this post we focus on commands messages and the resulting orchestration driven architectures. However, the same retry logic is also needed, in the receivers, when an action is triggered by an event message.
3 See A Note on Distributed Computing by J. Waldo for more information about failures and partial failures in distributed systems.